서론
캐시 스탬피드를 발견하고 많은 스레드가 DB를 동시 접근 하는 것을 방지하기 위해 다양한 방식의 해결법을 적용하던 과정에서 분산락을 적용했을 때 게시글을 조회하지 못하는 오류가 발생했습니다.
요약
| 캐시 | 평균 Throughput | 캐시 갱신 시 레디스 CPU 사용량 | 캐시 갱신 시 실행거부 오류 |
| 분산락 개선 전 | 235 | 0.06% | RejectedExecutionExeption 466건 |
| 분산락 개선 후 | 260 | 0.03% | 오류 0건 |
증상 요약
1. 캐시 스탬피드 해결
2. 커넥션 획득 시간 50배 감소
3. 레디스 메모리 사용량 1.8배 감소
4. TTL 만료시 비동기 스레드로 캐시 갱신을 할 때 RejectedExecutionExeption 발생
결론 요약
1. 비동기 스레드에서 waitTime을 설정해 스레드 풀 병목이 발생했다. waitTIme을 제거해 대기하지 않고 Fail fast로 반환하도록 조정했다
2. 비동기 로직에서 블로킹 락을 논 블로킹 락으로 바꾸었다.
3. 많은 스레드들이 순차적으로 락이 필요한 상황이 아니라면 waittime을 설정하지 않는 것이 Redis의 CPU리소스를 아끼고 조금 더 빠른 응답 반환이 가능하다.
깨달은 점
1. 락 획득 시점은 비동기에서 획득 하여도 된다. 락 획득 시점이 비동기에 있다고 병목이 일어나는 것이 아니다. 잘못된 설계 때문에 일어나는 것이기 때문에 애플리케이션 요구사항에 따라 동기, 비동기 중 적절한 지점을 선택하면 된다.
2. 비동기 로직에서 블로킹 락을 기다리는 것은 옳지않은 설계이다 스레드가 멈추지 않는 것을 가정한 상태에서 강제로 멈추기 때문이다.
3. waittime을 설정하면 RLock에서 채널을 개설한다. 이는 Redis의 CPU에 영향이 가므로 순차적인 락 경합 (추첨 이벤트 등)이 필요한 상황이 아니라면 waittime을 설정하지 않는 것이 유리하다.
구현 코드
Redisson과 비동기 설정
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient() {
config.setThreads(8); // 애플리케이션 스레드
config.setNettyThreads(8); // Pub/Sub 발행을 생각하여 Netty 설정
return Redisson.create(config);
}
}
@Bean(name = "cacheRefreshExecutor")
public ThreadPoolTaskExecutor cacheRefreshExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2); // 기본 스레드 수
executor.setMaxPoolSize(8); // 최대 스레드 수
executor.setQueueCapacity(50); // 대기열 크기
executor.setThreadNamePrefix("cache-refresh-");
executor.initialize();
return executor;
}
아래는 캐시 조회 로직입니다. TTL 만료시 캐시 갱신 로직에 접근합니다.
비동기 캐시 갱신 로직에서는 락을 획득하면 2차캐시로부터 글 ID목록을 받아 DB 조회 후 1차캐시에 업데이트 합니다.
public List<PostSimpleDetail> getWeeklyPosts() {
try {
Long ttl = TTL확인(PostCacheFlag.WEEKLY);
List<PostSimpleDetail> currentCache = 캐시반환(PostCacheFlag.WEEKLY);
// TTL이 없거나 만료되었으면 캐시 갱신
if (ttl == null || ttl <= 0) {
cacheRefreshService.asyncRefreshCache(PostCacheFlag.WEEKLY);
}
// 캐시 반환
// 갱신 이후 다음 스레드 부터 갱신된 캐시를 반환 받습니다.
return currentCache;
} catch (Exception e) {
throw new CustomException(ErrorCode.POST_REDIS_WEEKLY_ERROR, e);
}
}
// 비동기 캐시 갱신 로직
@Async("cacheRefreshExecutor")
public void asyncRefreshCache(PostCacheFlag type) {
boolean acquired = 락 획득(PostCacheFlag.WEEKLY);
if (!acquired) {
log.info("다른 스레드가 캐시 갱신 중: type={}", PostCacheFlag.WEEKLY);
return;
}
try {
List<Long> storedPostIds;
storedPostIds = 2차캐시로부터 조회할 게시글 ID 반환(type);
List<PostSimpleDetail> refreshed = DB조회(storedPostIds)
캐시 갱신(type, refreshed);
} catch (Exception e) {
log.error("캐시 갱신 에러: 타입={}", type, e);
} finally {
락 해제(type);
}
}
// RLOCK의 락 획득 로직입니다.
public boolean 락획득(PostCacheFlag type) {
String lockKey = "lock:cache:refresh:" + type.name();
RLock lock = redissonClient.getLock(lockKey);
try {
// waittime 3초 leasetime 5초로 설정했습니다.
boolean acquired = lock.tryLock(3, 5, TimeUnit.SECONDS);
return acquired;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.warn("캐시 갱신 락 획득 중 인터럽트 발생: type={}", type, e);
return false;
}
}
Redisson에 대해서
Redisson의 tryLock()
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long time = unit.toMillis(waitTime);
long current = System.currentTimeMillis();
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
// 락 획득 시도
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
current = System.currentTimeMillis();
// 락 획득 실패 시 락 채널 구독
// subscribe 내부에서는 내부적으로 세마포어로 동시성제어를 합니다.
// 하나의 채널에 너무 많은 구독을 생성하지 않도록,
// 한번에 하나의 스레드만 subscribe를 할수있도록 기존 구독이 있다면 재사용하는 역할 입니다.
CompletableFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId);
try {
subscribeFuture.get(time, TimeUnit.MILLISECONDS);
} catch (TimeoutException e) {
if (!subscribeFuture.completeExceptionally(new RedisTimeoutException(
"Unable to acquire subscription lock after " + time + "ms. " +
"Try to increase 'subscriptionsPerConnection' and/or 'subscriptionConnectionPoolSize' parameters."))) {
subscribeFuture.whenComplete((res, ex) -> {
if (ex == null) {
unsubscribe(res, threadId);
}
});
}
acquireFailed(waitTime, unit, threadId);
return false;
} catch (ExecutionException e) {
LOGGER.error(e.getMessage(), e);
acquireFailed(waitTime, unit, threadId);
return false;
}
try {
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
while (true) {
long currentTime = System.currentTimeMillis();
ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
// 락 획득 시도
if (ttl == null) {
return true;
}
// 실패시 락의 TTL 만큼 스레드를 timed_wating으로 만듭니다.
time -= System.currentTimeMillis() - currentTime;
// 대기 시간이 끝나면 밖으로 나옵니다.
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
// waiting for message
currentTime = System.currentTimeMillis();
if (ttl >= 0 && ttl < time) {
commandExecutor.getNow(subscribeFuture).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
commandExecutor.getNow(subscribeFuture).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
}
} finally {
// 마지막에는 채널을 구독해제 합니다.
unsubscribe(commandExecutor.getNow(subscribeFuture), threadId);
}
// return get(tryLockAsync(waitTime, leaseTime, unit));
}락 획득 실패시 락 채널을 구독합니다. 락의 TTL 만큼 스레드를 timed_waiting으로 만들고 대기시간이 끝날때까지 반복합니다.
대기시간이 끝나면 채널을 구독해제하고 밖으로 나갑니다. 그리고 waittime이 없을 시 구독 자체를 안하는 것을 확인할 수 있습니다.
waittime이란 락 획득에 실패한 스레드가 다음 기회를 노리기 위해 채널을 구독하는 것이고 캐시 스탬피드 상황에서는 waittime을 설정하지 않고 subscribe에 자원을 낭비하는 것을 막는 것이 좋습니다.
Redisson의 unlock()
protected CompletableFuture<Void> unlockInnerAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"... Lua script ...",
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; ",
Arrays.asList(getRawName(), getChannelName()),
LockPubSub.UNLOCK_MESSAGE
);
} Lua Script로 채널에 언락 메시지를 보내는것을 알 수 있습니다.
캐시 스탬피드의 상황 확인
커넥션 풀 지표
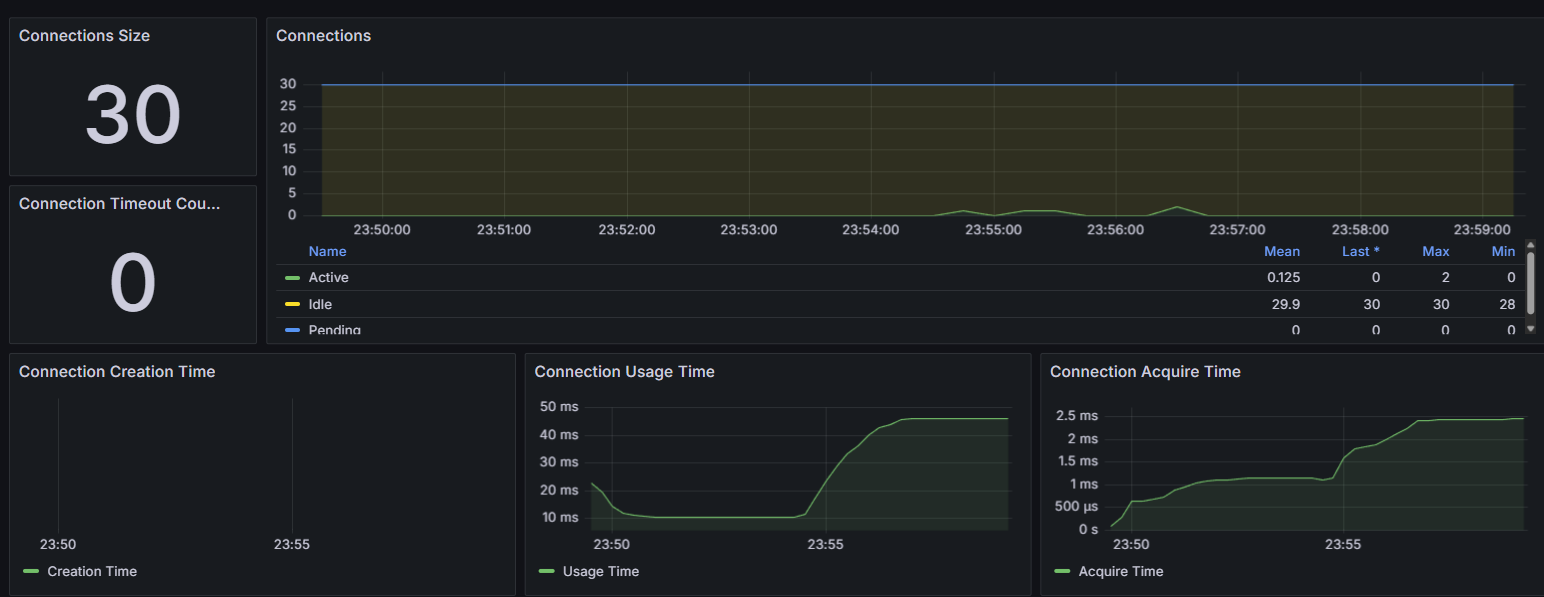
TTL 만료 시간에도 커넥션 요청이 몰리지 않았습니다.
사실 DB커넥션이 요청이 많아지지 않을 뿐이지 스탬피드 상황에서 에러가 반환된 것을 보면 해결한 것으로 볼 수 없습니다.
레디스의 Hit / Miss 지표

락 적용 이전과 다르게 TTL 만료시간에 Hit가 급 감소하지 않았습니다.
Pub/Sub의 작동

펍섭 명령이발생하여 채널이 생성되어 제대로 락을 수행하고 있다는 것을 알 수 있습니다.
원인 추적
2025-12-25 15:53:05.823 Caused by: java.util.concurrent.RejectedExecutionException:
Task java.util.concurrent.FutureTask@5c211e3a[Not completed,
task = org.springframework.aop.interceptor.AsyncExecutionInterceptor
$$Lambda/0x0000724c090af8a8@254eb0ad] rejected from
org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor$1@2aeef1ca
[Running, pool size = 8, active threads = 8, queued tasks = 50, completed tasks = 120]위는 스택트레이스의 일부입니다. 비동기 스레드 풀이 가득차고 대기열이 꽉차서 에러가 난 것을 확인 할 수 있습니다.
에러를 모니터링하기 위해서 10초마다 캐시 갱신 비동기 스레드 풀의 상태를 로깅하였습니다.
@Component
@Slf4j
public class AsyncExecutorStatusLogger {
private final ThreadPoolTaskExecutor cacheRefreshExecutor;
public AsyncExecutorStatusLogger(@Qualifier("cacheRefreshExecutor") ThreadPoolTaskExecutor cacheRefreshExecutor) {
this.cacheRefreshExecutor = cacheRefreshExecutor;
}
@Scheduled(fixedRate = 10000) // 10초마다 실행
public void monitorExecutor() {
int activeCount = cacheRefreshExecutor.getActiveCount();
int poolSize = cacheRefreshExecutor.getPoolSize();
int queueSize = cacheRefreshExecutor.getThreadPoolExecutor().getQueue().size();
log.info("[Monitor] 활성: {}, 풀크기: {}, 대기열: {}", activeCount, poolSize, queueSize);
}
}
비동기 캐시 갱신 스레드 풀의 로깅
// 테스트 시작 5분 후 첫번째 캐시스탬피드 상황의 비동기 스레드 풀
2025-12-25 06:47:44.753 [scheduling-1] INFO j.b.i.monitor.AsyncExecutorStatusLogger
[trace=none user=anonymous ip=] - [Monitor] 활성: 8, 풀크기: 8, 대기열: 29
// 테스트 시작 10분 후 (끝나기 직전) 두번째 캐시 스탬피드 상황의 비동기 스레드 풀
2025-12-25 06:53:02.623 [scheduling-1] INFO j.b.i.monitor.AsyncExecutorStatusLogger
[trace=none user=anonymous ip=] - [Monitor] 활성: 8, 풀크기: 8, 대기열: 50
2025-12-25 06:52:52.623 [scheduling-1] INFO j.b.i.monitor.AsyncExecutorStatusLogger
[trace=none user=anonymous ip=] - [Monitor] 활성: 8, 풀크기: 8, 대기열: 50이 스레드풀은 8개의 스레드가 동작하며 50개의 스레드까지 대기 할 수 있게 설정했습니다.
첫번째 스탬피드 상황에 29개의 스레드가 대기하는것을 확인할수 있습니다.
두번째 스탬피드 상황에서는 50개의 스레드가 대기하여 대기열이 가득찬 것을 확인할 수 있습니다.
비동기 스레드풀의 병목으로 에러가 반환된 것을 확인하였습니다.
10초마다 로깅하여 정확하지는 않지만
첫번째 스탬피드 상황은 아직 부하가 완벽하게 램프업되지않았고 (초당 요청 150건) 다음 10초에는 병목이 해소된것을 확인하였습니다.
두번째 스탬피드 상황에는 부하가 완벽하게 램프업대어 (초당 요청 300건) 10초가 지나도 대기큐가 줄어들지 않았습니다.

실제로 그래프를 보면 두번째 스탬피드를 감당하지 못하고 TPS가 30으로 곤두박칠 친것을 볼 수 있습니다.
만약 테스트를 더 길게 잡았거나 더 많은 부하가 일어났다면 병목이 아주 심해지고 전체 시스템의 성능도 급격히 하락했을 겁니다.
해결 방안
이 증상의 문제는 캐시갱신을 위한 비동기 큐가 포화되는 것이고 그렇다면 원인은 waitTime에 있습니다.
락을 획득하지 못한 스레드들이 비동기 스레드 풀에 존재한채로 블로킹 되고 있기때문입니다.
현재 코드를 다시 보면 waitTime이 3초로 설정되어 있는 것을 볼 수 있습니다.
public boolean 락획득(PostCacheFlag type) {
String lockKey = "lock:cache:refresh:" + type.name();
RLock lock = redissonClient.getLock(lockKey);
try {
// waittime 3초 leasetime 5초로 설정했습니다.
boolean acquired = lock.tryLock(3, 5, TimeUnit.SECONDS);
return acquired;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.warn("캐시 갱신 락 획득 중 인터럽트 발생: type={}", type, e);
return false;
}
}근본적으로는 비동기 스레드에서 블로킹 락을 대기하고 있는 설계 결함입니다.
처음엔 락 획득 지점을 동기적으로 변경해야한다고 생각했으나, 스레드가 멈추지 않는 것을 가정한 상태에서 강제로 멈추는 설계결함임을 인지했고 동기적으로 락을 취득하게하면 모든 스레드가 락 획득 시도를 해보기 때문에 오류는 해결되었지만 오히려 성능이 더 내려갔습니다.
따라서 논블로킹으로 락 획득로직으로 바꾸어 비동기 로직의 설계에 맞게 했습니다. 블로킹이라도 waittime이 0이라 큰 차이는 나지않습니다만 설계의 문제와 waittime이 0이라도 일어나는 아주 잠깐의 블로킹을 막고자합니다.
개선
개선 이전 로직
public boolean 락획득(PostCacheFlag type) {
String lockKey = "lock:cache:refresh:" + type.name();
RLock lock = redissonClient.getLock(lockKey);
try {
// waittime 3초 leasetime 5초로 설정했습니다.
boolean acquired = lock.tryLock(3, 5, TimeUnit.SECONDS);
return acquired;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.warn("캐시 갱신 락 획득 중 인터럽트 발생: type={}", type, e);
return false;
}
}// 비동기 캐시 갱신 로직
@Async("cacheRefreshExecutor")
public void asyncRefreshCache(PostCacheFlag type) {
boolean acquired = 락 획득(PostCacheFlag.WEEKLY);
if (!acquired) {
log.info("다른 스레드가 캐시 갱신 중: type={}", PostCacheFlag.WEEKLY);
return;
}
try {
List<Long> storedPostIds;
storedPostIds = 2차캐시로부터 조회할 게시글 ID 반환(type);
List<PostSimpleDetail> refreshed = DB조회(storedPostIds)
캐시 갱신(type, refreshed);
} catch (Exception e) {
log.error("캐시 갱신 에러: 타입={}", type, e);
} finally {
락 해제(type);
}
}
개선 이후 로직
public RFuture<Boolean> 락획득비동기(PostCacheFlag type) {
String lockKey = "lock:cache:refresh:" + type.name();
RLock lock = redissonClient.getLock(lockKey);
// tryLockAsync는 즉시 RFuture를 반환하고 스레드를 해제함
// waitTime 0, leaseTime 5s
return lock.tryLockAsync(0, 5, TimeUnit.SECONDS);
}@Async("cacheRefreshExecutor")
public void asyncRefreshCache(PostCacheFlag type) {
String lockKey = "lock:cache:refresh:" + type.name();
RLock lock = redissonClient.getLock(lockKey);
락획득비동기(type).whenComplete((acquired, throwable) -> {
if (throwable != null) {
log.error("락 획득 중 시스템 에러 발생: type={}", type, throwable);
return;
}
if (!acquired) {
log.info("다른 스레드가 캐시 갱신 중: type={}", type);
return;
}
try {
log.info("캐시 갱신 시작: type={}", type);
// 여기서부터는 어차피 스레드가 점유되지만 2티어 비동기로 설계하여
// HTTP응답에는 영향을 주지않고 단 하나의 스레드만 블로킹 됩니다.
List<Long> storedPostIds = 2차캐시로부터조회할게시글ID반환(type);
List<PostSimpleDetail> refreshed = DB조회(storedPostIds);
캐시갱신(type, refreshed);
} catch (Exception e) {
log.error("캐시 갱신 로직 실행 중 에러: type={}", type, e);
} finally {
// 비동기 방식으로 락 해제
lock.unlockAsync();
}
});
}현재 상황에서는 단 하나의 스레드만 락을 얻으면 되기에 waittime을 삭제하여 불 필요한 대기를 막고 채널의 구독을 막아 리소스를 절약하고 락을 획득하지 못한 스레드들은 즉시 이전 캐시를 반환하게 하여 응답속도를 높였습니다.
또한 논블로킹 락으로 대체하였고 락을 획득하지못하면 즉시 과거의 캐시를 반환하게 하였습니다.
결과

개선 이후에 펍섭이 실제로 생성되지 않았습니다.


CPU에 부하가 있는것은 아니었지만 펍섭의 삭제로 CPU 사용량을 0.06%에서 0.03%로 절약했습니다.
개선 이전 두번째 스탬피드에서는 비동기 스레드 풀의 병목으로 연결이 거부되어 아이러니하게 Redis의 CPU가 할일을 덜어준 모습니다.
개선 이후에는 두번째 스탬피드에도 병목이 없어 정상적으로 레디스가 CPU를 사용하는 모습을 볼 수 있습니다.
| 캐시 | 평균 Throughput | 캐시 갱신 시 레디스 CPU 사용량 | 캐시 갱신 시 실행거부 오류 |
| 분산락 개선 전 | 235 | 0.06% | RejectedExecutionExeption 466건 |
| 분산락 개선 후 | 260 | 0.03% | 오류 0건 |
'트러블슈팅과 고민 > 트러블슈팅' 카테고리의 다른 글
| 작성자 검색 인덱스 사용 불가 문제 해결 (0) | 2025.11.25 |
|---|---|
| 배치 기반 친구 추천 API의 실시간 전환 (0) | 2025.11.23 |
| Redis TTL 만료 시점 병목 해소: Cache Stampede 방어 전략 측정 및 분석 (0) | 2025.11.03 |
| 하이버네이트 커넥션 해제 로직의 커넥션 누수 결함 개선 (0) | 2025.10.19 |
| 게시판 유저 상호작용 부하 테스트 및 성능 개선 (0) | 2025.08.07 |


